
한국에너지공과대학교 (총장 윤의준, 이하 KENTECH) 이석주 교수 연구팀이 KAIST (총장 이광형) 권인소 교수, Francois Rameau 연구교수, DGIST (총장 국양) 임성훈 교수와 공동연구를 통해 자율주행의 핵심 기술 중 하나인 동적 물체의 3차원 시각인지를 위한 인공지능 학습 알고리즘을 개발하는데 성공했다고 10일 밝혔다.
레벨3 이상의 자율주행을 구현하기 위해 3차원 공간인지(깊이 정보 및 움직임 추론 등)기술은 필수적이다. 이를 위해 업계에서는 라이다(LiDAR)나 레이더(RADAR) 등의 센서를 통해 직접 3차원 정보를 취득하거나, 카메라로부터 얻은 영상을 깊이 지도로 추정하는 알고리즘을 연구해왔다. 대표적인 기업으로 테슬라가 카메라 기반의 자율주행 기술을 개발해왔다.
딥 러닝 기술의 고도화로 3차원 인식 기법들의 비약적인 발전에도 불구하고, 영상 기반의 깊이 지도 추정은 학습 단계에서 큰 단점이 있다. 바로 한 대의 카메라만으로는 3차원 공간에 대한 인공신경망 학습이 크게 제한된다는 점이다.
영상정보만으로 깊이 정보를 학습하기 위해서는 라이다 혹은 레이더로부터 취득한 깊이 값을 AI 모델에 학습하거나, 스테레오 카메라로부터 좌우 영상의 시차를 통해 거리를 학습한다. 위의 경우, 학습 단계에서 부가적인 센서가 필요하며 학습 비용이 상승한다. 다음으로 카메라의 움직임으로부터 3차원 구조를 복원하는 Structure-from-Motion (SfM) 알고리즘을 활용한 학습 방법이 존재하지만, 주행 환경처럼 동적 물체가 포함된 영상이 학습데이터에 존재할 경우, 물체에 대한 깊이 정보 추정 성능이 크게 저하되며 동적 물체의 움직임 추정이 불가능하다는 단점을 가진다.
테슬라와 구글, 도요타를 비롯한 유수의 기관들도 이러한 한계를 극복하고 깊이 정보 추정 성능을 높이기 위해 다양한 방법론들을 제안해왔지만 일반화된 근본적인 해결책은 확립되지 않은 실정이다.
KENTECH 이석주 교수 연구팀은 한쪽 눈만 보여도 운전면허 취득이 가능하다는 점에서 영감을 얻어 복잡한 동적 환경에서 인간이 3차원 정보를 인지할 때 활용하는 객체에 대한 사전지식에 초점을 맞췄다.
예를 들어, 사람은 일반적으로 보행자보다 자동차가 빠르게 움직일 것이고, 승용차는 버스 보다 높이가 낮기 때문에 만일 영상에서 이 둘의 높이가 같다면 버스가 더 멀리 위치할 것이고, 차량의 움직임은 회전보다 직진의 비중이 높을 것 등을 이미 인지하고 있다.
이러한 객체 정보는 다양한 물체 인지 태스크들이 서로 유기적으로 맞물려 동시에 효과적으로 학습되도록 AI 모델들 간의 윤활유 역할을 한다.
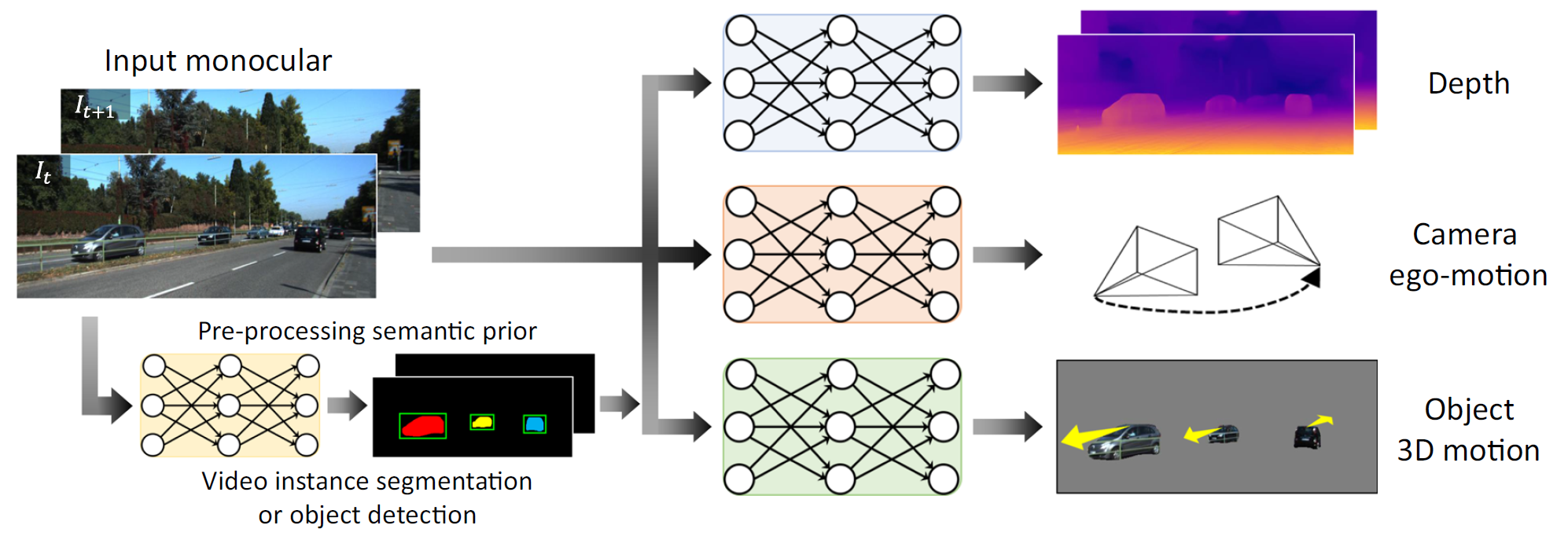
연구팀은 깊이 지도 생성, 카메라의 움직임 추정, 동적 물체의 움직임 추정을 위한 세 가지 신경망들을 제안하고, 이들을 동시에 학습하기 위해 객체에 대한 사전지식을 통한 새로운 자기지도 학습 메커니즘을 설계하였다.
이때, 낮은 수준과 높은 수준의 다양한 객체 정보를 사람처럼 해석할 수 있도록 알고리즘들을 개발하고 이들을 인공지능 학습기에 통합하였다.
결과적으로, 단안 카메라 학습에 대한 깊이 지도와 움직임 추정 태스크에서 기존의 인식 성능을 뛰어넘었고, 다양한 동적 주행 환경에서도 일관적으로 우수한 성능을 보였다.
이석주 교수는 “단일 태스크만 학습하는 기존의 AI 모델은 한계가 있기 때문에 서로 다른 목적을 가진 AI 모델들이 유기적으로 학습될 때 새로운 가치가 창출될 것”이라며 “본 연구를 기점으로 향후 인공지능 기술의 방향을 제시할 연구에 기여할 것”이라고 말했다.
개발된 알고리즘을 활용하면 기존의 영상 기반 3차원 인식 시스템의 약점을 크게 보완할 수 있고, 나아가 다양한 로봇과 인공지능 분야에 광범위하게 응용될 수 있을 것으로 기대된다.
KENTECH 에너지공학부 이석주 교수가 주 저자로 참여하고, KAIST 권인소 교수, Francois Rameau 연구교수와 DGIST 임성훈 교수가 함께 참여했다.
이 연구성과는 독일과 영국에서 설립된 Springer Nature 출판사의 국제학술지 International Journal of Computer Vision에 온라인으로 7월 19일 실렸으며 (논문명: Self-Supervised Monocular Depth and Motion Learning in Dynamic Scenes: Semantic Prior to Rescue),
이번 연구는 한국에너지공과대학교와 한국과학기술원, 대구경북과학기술원의 지원으로 수행됐다.


